

Introduction
Decentralized protocols, including emergent ones such as Nostr are trying to figure out the best way to store and distribute non-text data outside of centralized servers. For Nostr particularly, there are home-grown solutions such as nostr.build that offers image and video storage on their servers both free of charge and for a fee. These services can suffer from being inherently centralized and shutdown by their respective hosting platforms.
Other proposals have been to use existing decentralized protocols such as Bittorrent or IPFS. While these currently have utility for some use cases, they can suffer from long load times and failure to retrieve requested content. Another issue is the overhead of setup needed both for running a decentralized client and running a node
Proposal
The proposed design for decentralized data storage will be to use media relay servers that work over the websockets protocol. The design will be similar to the Nostr protocol architecture, where multiple relays can store the same data signed with a keypair. This design will help with storage persistence, that can be lost with p2p protocols, and has little overhead on both the client or server side.
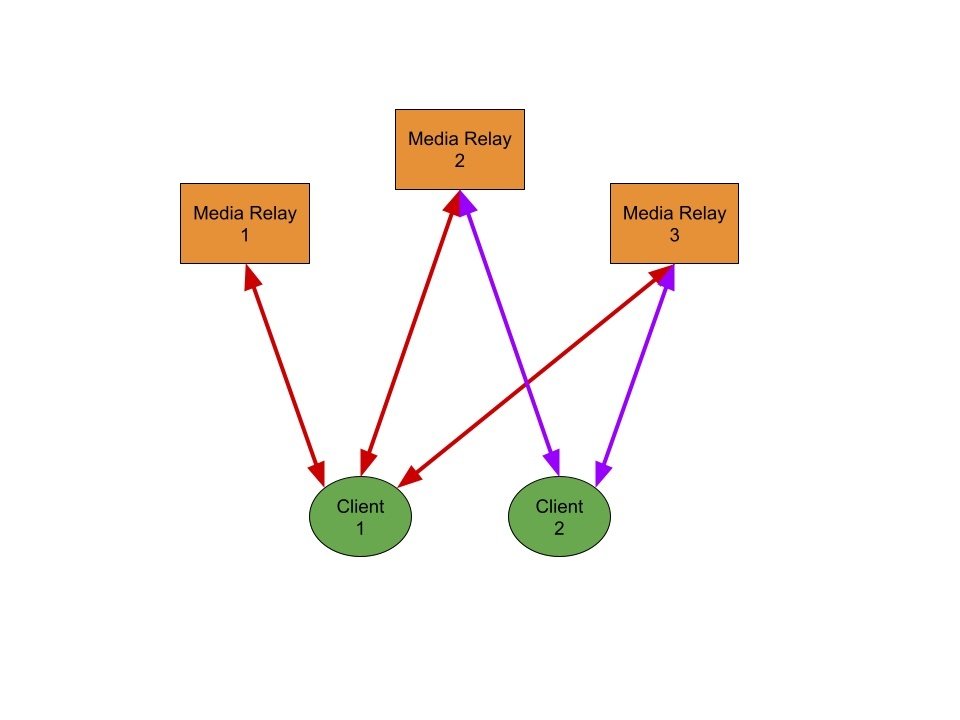
How it works
From a high level the media relay will act as storage for signed binary data (blobs). Each piece of data will have a pointer associated that allows for indexing, searching, and retrieval. The blobs of data and pointers will not have any additional information or context about the data stored on the relay. All the relay will “know” is that there is data of a certain size that has been confirmed to be referenced by an associated keypair. This means that a relay operator cannot discern if a blob is an image, executable, or any other type of data without further work.
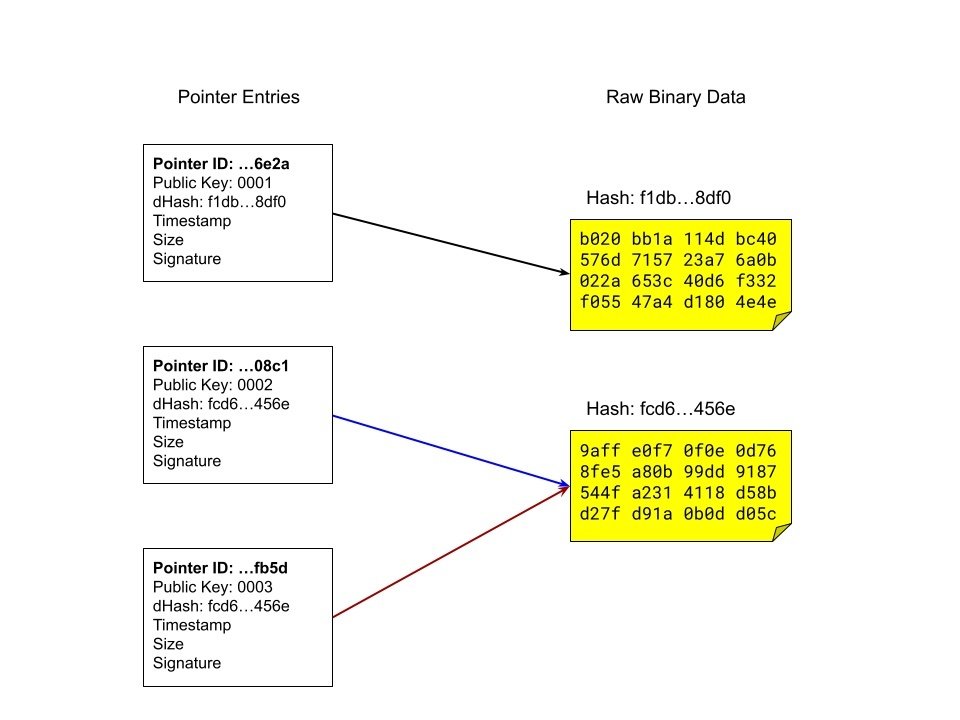
Pointers
Pointers on a media relay represent a signed entry for a blob of data. A blob can only exist on a relay if it has one or more pointers associated with it. A pointer consists of an id, public key associated with the data, a timestamp of when the pointer was created, the SHA-256 hash of the blob that the pointer is referencing, blob size, and signature signing the pointer. This is very similar to the concept of a Nostr event and this allows clients to look up references and confirm a blob exists without having to download multiple amounts of data.
Multiple pointers can exist for a blob of data. This is similar to multiple users uploading the same file to an image service. Some amount of deduplication may occur to prevent a waste of space. In a media relay something similar occurs. If multiple users upload identical data, the media relay will test it as 2 pointers referencing the same data.
When there are no longer any pointers associated with a blob, the media relay will discard the data. Pointers are needed to download or get information on a blob.
Raw storage
The media relays will hold blobs of binary data on their servers. This blob itself will have no labels or context and will just appear as data of a certain length. The maximum length of the blob will be determined by the media relay such as being able to store a blob at a maximum size of 100KB.
If a logical file such as an executable or video is several megabytes in size, a client will break up the data into multiple blocks. Those blocks will each have a blob of a determined size, smaller than the maximum blob size, and a pointer associated with the blob. A relay will have no correlation between the multiple pointers and blobs, as that will be determined by the uploading client and later by a file descriptor.
File descriptors
A file descriptor is metadata that provides instructions on how to retrieve and recreate a logical file from a media relay. Since a media relay has no information on a file, file type, or total size, a file descriptor describes the file type and how to access each block of data.
Each block of data in a file descriptor will reference the id of the pointer, media relays to use, blob size, blob hash. In this way a file descriptor can instruct a client to pull data from several different media relays.
In Nostr specifically a file descriptor will be in the form of a replaceable event and will be referenced using an naddr1 bech32 label. These can then be used by different Nostr clients instead of a traditional URL to reference an image, video, or other media.
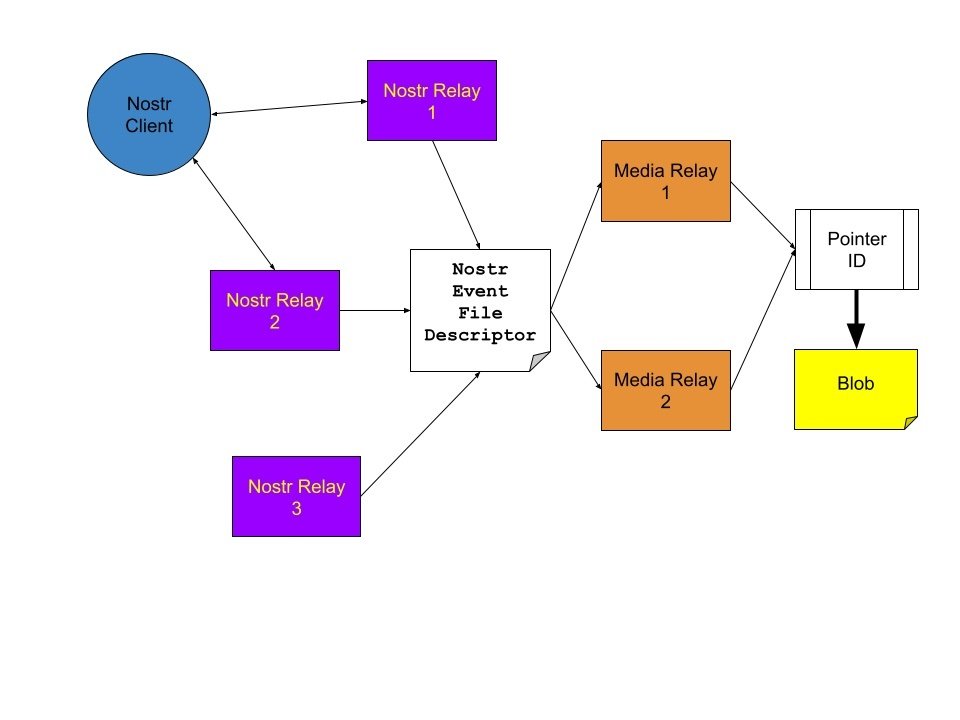
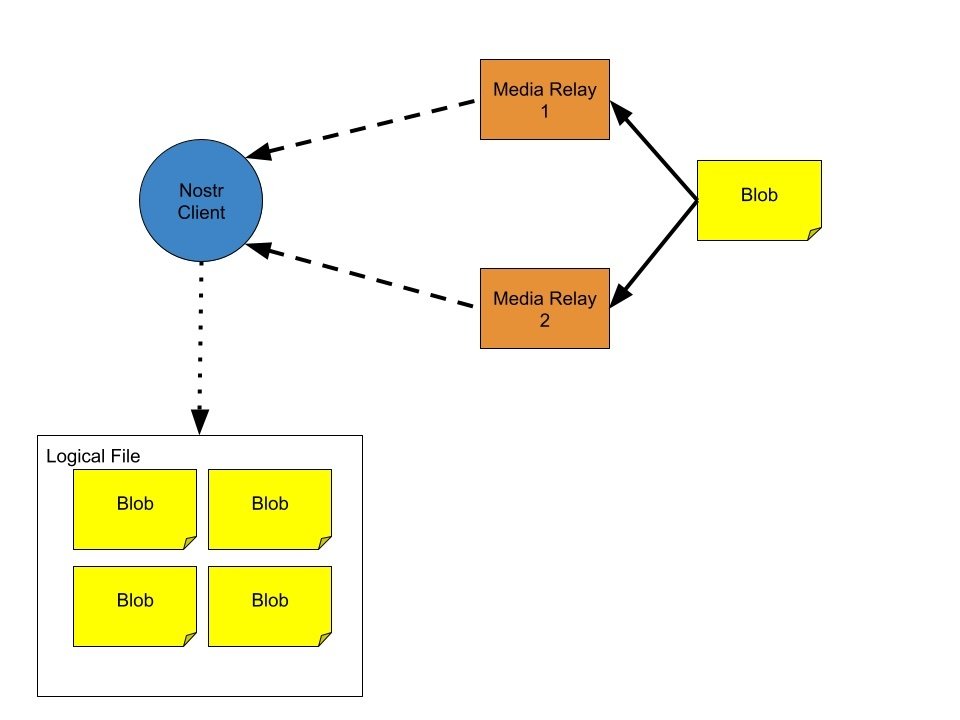
Client Activity
When a client encounters a file descriptor, whether in the form of an naddr1 or in another format, it should be able to read the media data to know what type of file to expect. It should also be able to read and pull down each partition of the file, represented as a pointer id to a set of media relays.
The client would pull down each part either sequentially (if it’s described as a stream) or in random order. In the former case a client would read each piece and process it appropriately (i.e. a media player). In the latter case, the file may be put together according to the file descriptor.
Decentralization Goals
This method of decentralized data storage will only work if there are multiple relays across multiple geographical areas that can provide redundancy and distribution of data. The media relays themselves will not transmit information across to other media relays and there will not be a shared, synced database of pointers and databases.
Challenges
Some of the challenges surrounding having media relays revolve the following: * Incentives to run a media relay * Spam prevention * Moderation * Discovery of relays * Data permanence
Incentives
Similar to some of the concerns about running Nostr relays long-term, media relays will cost money to run in some form given the storage and bandwidth usage. There may need to be public key based subscriptions that allow a user to store and/or point to a quota of storage.
The media relay set up will not have a built in token or monetary structure built in and these may happen out-of-band of the media relays. For example, using Lightning to pay for 5 GB of storage which will instruct a media relay to allow 5 GB of blobs to be stored and pointed to.
Spam Prevention
As with other decentralized solutions, spam is a big factor as a media relay will have a finite amount of storage and bandwidth that could be abused. Spam prevention measures and subscriptions against discrete public keys could help mitigate this problem.
Moderation
While the nature of running a media relay is that context is not inherently known about a file, there could be issues within certain jurisdictions where a select set of blobs are part of illegal media.
Unless a file descriptor is provided or certain heuristics (i.e. putting together a set of blobs associated with a public key with similar timestamps) are performed on blobs of data, this may not be known beforehand and moderation may be best-effort at best.
Discovery of relays
There may be some difficulty in knowing which media relays to use without having some sort of centralized site that publishes a set of known relays. This can have a risk of centralization of only some relays are known and used by everyone.
There may be some solutions such as relay operators publishing their relays on nostr or other decentralized protocols. A tradeoff on verifying these relays and finding them may always exist.
Data Permanence
This may always be a tradeoff with a decentralized protocol where the data isn’t directly p2p from the owner of the data. Servers may go down, lose data, remove data, etc and those blobs may be lost on that media relay.
The best safeguard for having data available is to diversify over multiple relays. A file descriptor should have multiple media relays references for pointers and in the event of a host being down either temporarily or permanently, additional media relays can be used to pull the data down.
Questions I ask myself against media relays
Why not use Nostr relays?
I don’t think Nostr relays with a plain-text protocol will be the best way to store media in a scalable way. Images already have push back and from my own anecdotal observations relay operators do not want to assume the burden of Base64 content events.
There is also an issue of event requests that will pull the events (data and all) as opposed to where my idea for a media relay would be to only to query and pull down pointers based on search parameters. Data would be pulled on a specific request.
Why not use IPFS\Bittorrent?
These are slow in my experience and not very reliable. In their best use case, these protocols are great for larger files and wouldn’t provide a good experience for loading images or smaller binary data.
Why not a file descriptor of http servers?
Extra overhead of running a web server and running a servlet that pulls down the data rather than a specialized media relay.
I also want to utilize web sockets because they don’t run into the CORS issue.
It could still be a possibility.
Conclusion
As of today (October 6th), prototype code is being built for the following pieces: * Media Relay * Nostr event spec * Javascript Web and NodeJS client library
This may turn out to not be the best approach to decentralized storage for the Internet and it is worth trying to see where it ends up.
This is a very informal thought experiment I wanted to share with the wider world.